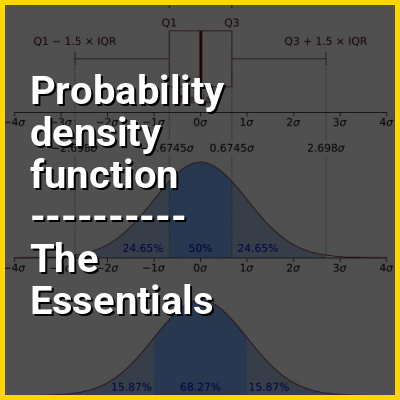
In probability theory, a probability density function (PDF), density function, or density of an absolutely continuous random variable, is a function whose value at any given sample (or point) in the sample space (the set of possible values taken by the random variable) can be interpreted as providing a relative likelihood that the value of the random variable would be equal to that sample. Probability density is the probability per unit length, in other words. While the absolute likelihood for a continuous random variable to take on any particular value is zero, given there is an infinite set of possible values to begin with. Therefore, the value of the PDF at two different samples can be used to infer, in any particular draw of the random variable, how much more likely it is that the random variable would be close to one sample compared to the other sample.
More precisely, the PDF is used to specify the probability of the random variable falling within a particular range of values, as opposed to taking on any one value. This probability is given by the integral of a continuous variable's PDF over that range, where the integral is the nonnegative area under the density function between the lowest and greatest values of the range. The PDF is nonnegative everywhere, and the area under the entire curve is equal to one, such that the probability of the random variable falling within the set of possible values is 100%.